
相信不少同学在维护老项目时,都遇到过在深深的 if else 之间纠缠的业务逻辑。面对这样的一团乱麻,简单粗暴地继续增量修改常常只会让复杂度越来越高,可读性越来越差,有没有固定的套路来梳理它呢?这里分享三种简单通用的重构方式。
什么是面条代码
所谓的【面条代码】,常见于对复杂业务流程的处理中。它一般会满足这么几个特点:
- 内容长
- 结构乱
- 嵌套深
我们知道,主流的编程语言均有函数或方法来组织代码。对于面条代码,不妨认为它就是满足这几个特征的函数吧。根据语言语义的区别,可以将它区分为两种基本类型:
if...if 型
这种类型的代码结构形如:
function demo (a, b, c) {
if (f(a, b, c)) {
if (g(a, b, c)) {
// ...
}
// ...
if (h(a, b, c)) {
// ...
}
}
if (j(a, b, c)) {
// ...
}
if (k(a, b, c)) {
// ...
}
}流程图形如:
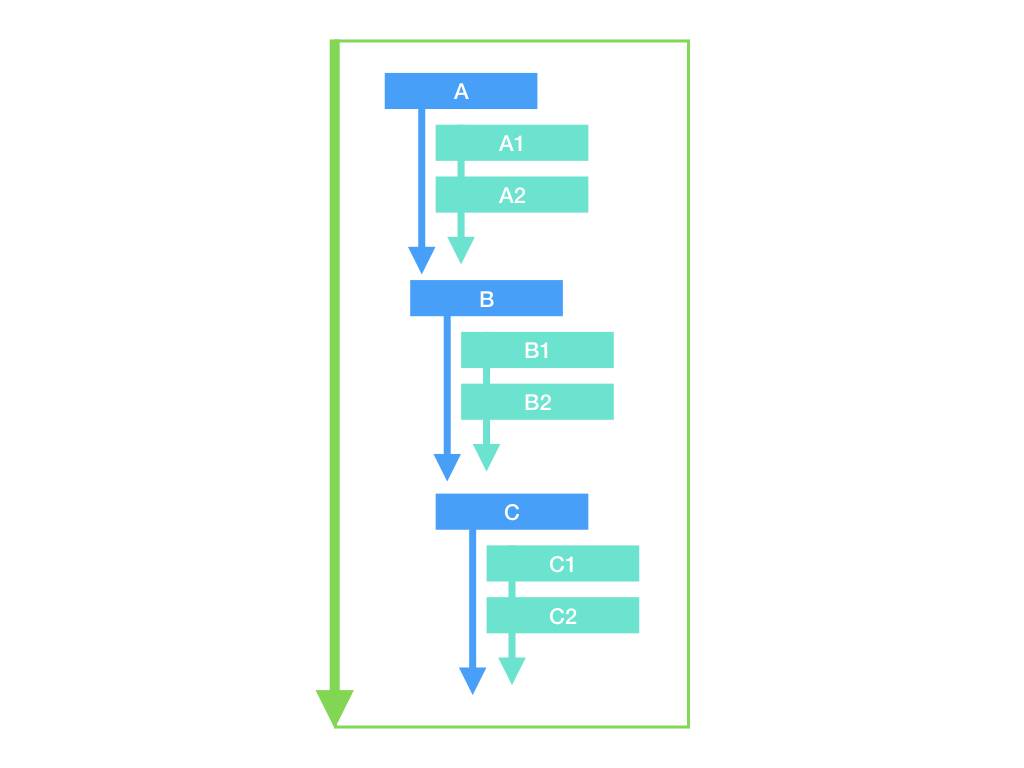
它通过从上到下嵌套的 if,让单个函数内的控制流不停增长。不要以为控制流增长时,复杂度只会线性增加。我们知道函数处理的是数据,而每个 if 内一般都会有对数据的处理逻辑。那么,即便在不存在嵌套的情形下,如果有 3 段这样的 if,那么根据每个 if 是否执行,数据状态就有 2 ^ 3 = 8 种。如果有 6 段,那么状态就有 2 ^ 6 = 64 种。从而在项目规模扩大时,函数的调试难度会指数级上升!这在数量级上,与《人月神话》的经验一致。
else if...else if 型
这个类型的代码控制流,同样是非常常见的。形如:
function demo (a, b, c) {
if (f(a, b, c)) {
if (g(a, b, c)) {
// ...
}
// ...
else if (h(a, b, c)) {
// ...
}
// ...
} else if (j(a, b, c)) {
// ...
} else if (k(a, b, c)) {
// ...
}
}流程图形如:

else if 最终只会走入其中的某一个分支,因此并不会出现上面组合爆炸的情形。但是,在深度嵌套时,复杂度同样不低。假设嵌套 3 层,每层存在 3 个 else if,那么这时就会出现 3 ^ 3 = 27 个出口。如果每种出口对应一种处理数据的方式,那么一个函数内封装这么多逻辑,也显然是违背单一职责原则的。并且,上述两种类型可以无缝组合,进一步增加复杂度,降低可读性。
但为什么在这个有了各种先进的框架和类库的时代,还是经常会出现这样的代码呢?个人的观点是,复用的模块确实能够让我们少写【模板代码】,但业务本身无论再怎么封装,也是需要开发者去编写逻辑的。而即便是简单的 if else,也能让控制流的复杂度指数级上升。从这个角度上说,如果没有基本的编程素养,不论速成掌握再优秀的框架与类库,同样会把项目写得一团糟。
重构策略
上文中,我们已经讨论了面条代码的两种类型,并量化地论证了它们是如何让控制流复杂度指数级激增的。然而,在现代的编程语言中,这种复杂度其实是完全可控的。下面分几种情形,列出改善面条代码的编程技巧。
基本情形
对看起来复杂度增长最快的 if...if 型面条代码,通过基本的函数即可将其拆分。下图中每个绿框代表拆分出的一个新函数:
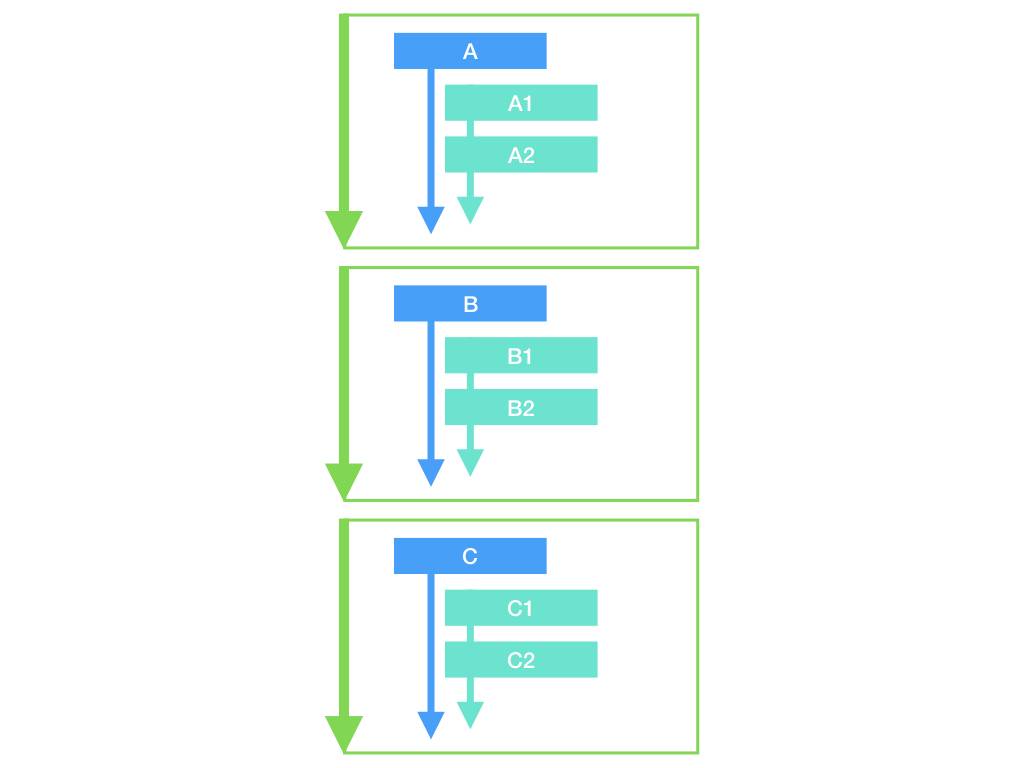
由于现代编程语言摒弃了 goto,因此不论控制流再复杂,函数体内代码的执行顺序也都是从上而下的。因此,我们完全有能力在不改变控制流逻辑的前提下,将一个单体的大函数,自上而下拆逐步分为多个小函数,而后逐个调用之。这是有经验的同学经常使用的技巧,具体代码实现在此不做赘述了。
需要注意的是,这种做法中所谓的不改变控制流逻辑,意味着改动并不需要更改业务逻辑的执行方式,只是简单地【把代码移出去,然后用函数包一层】而已。有些同学可能会认为这种方式治标不治本,不过是把一大段面条切成了几小段,并没有本质的区别。
然而真的是这样吗?通过这种方式,我们能够把一个有 64 种状态的大函数,拆分为 6 个只返回 2 种不同状态的小函数,以及一个逐个调用它们的 main 函数。这样一来,每个函数复杂度的增长速度,就从指数级降低到了线性级。
这样一来,我们就解决了 if...if 类型面条代码了,那么对于 else if...else if 类型的呢?
查找表
对于 else if...else if 类型的面条代码,一种最简单的重构策略是使用所谓的查找表。它通过键值对的形式来封装每个 else if 中的逻辑:
const rules = {
x: function (a, b, c) { /* ... */ },
y: function (a, b, c) { /* ... */ },
z: function (a, b, c) { /* ... */ }
}
function demo (a, b, c) {
const action = determineAction(a, b, c)
return rules[action](a, b, c)
}每个 else if 中的逻辑都被改写为一个独立的函数,这时我们就能够将流程按照如下所示的方式拆分了:
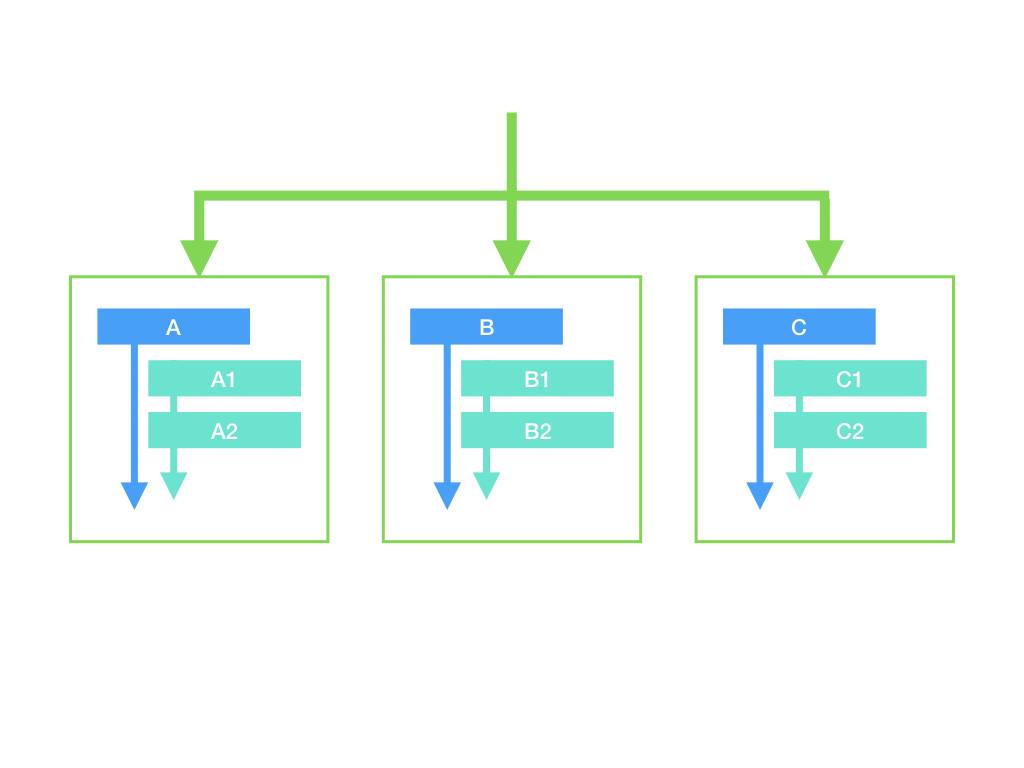
对于先天支持反射的脚本语言来说,这也算是较为 trivial 的技巧了。但对于更复杂的 else if 条件,这种方式会重新把控制流的复杂度集中到处理【该走哪个分支】问题的 determineAction中。有没有更好的处理方式呢?
职责链模式
在上文中,查找表是用键值对实现的,对于每个分支都是 else if (x === 'foo') 这样简单判断的情形时,'foo' 就可以作为重构后集合的键了。但如果每个 else if 分支都包含了复杂的条件判断,且其对执行的先后顺序有所要求,那么我们可以用职责链模式来更好地重构这样的逻辑。
对 else if 而言,注意到每个分支其实是从上到下依次判断,最后仅走入其中一个的。这就意味着,我们可以通过存储【判定规则】的数组,来实现这种行为。如果规则匹配,那么就执行这条规则对应的分支。我们把这样的数组称为【职责链】,这种模式下的执行流程如下图:
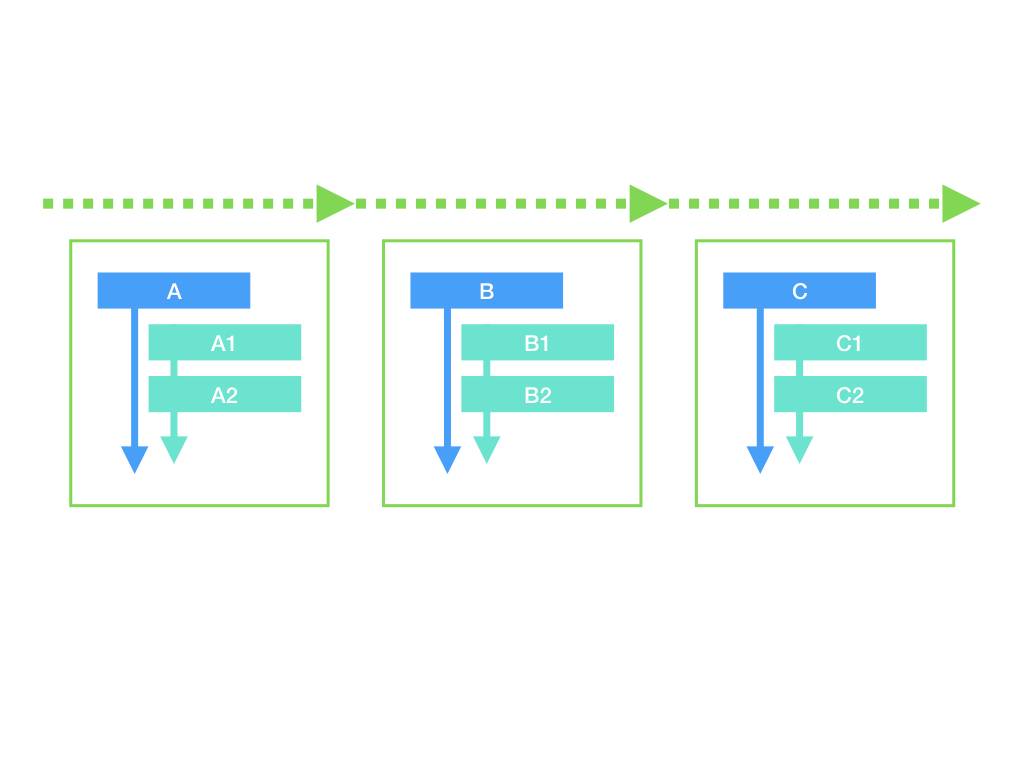
在代码实现上,我们可以通过一个职责链数组来定义与 else if 完全等效的规则:
const rules = [
{
match: function (a, b, c) { /* ... */ },
action: function (a, b, c) { /* ... */ }
},
{
match: function (a, b, c) { /* ... */ },
action: function (a, b, c) { /* ... */ }
},
{
match: function (a, b, c) { /* ... */ },
action: function (a, b, c) { /* ... */ }
}
// ...
]rules 中的每一项都具有 match 与 action 属性。这时我们可以将原有函数的 else if 改写对职责链数组的遍历:
function demo (a, b, c) {
for (let i = 0; i < rules.length; i++) {
if (rules[i].match(a, b, c)) {
return rules[i].action(a, b, c)
}
}
}这时每个职责一旦匹配,原函数就会直接返回,这也完全符合 else if 的语义。通过这种方式,我们就实现了对单体复杂 else if 逻辑的拆分了。
总结
面条代码其实容易出现在不加思考的【糙快猛】式开发中。很多简单粗暴地【在这里加个 if,在那里多个 return】的 bug 修复方式,再加上注释的匮乏,很容易让代码可读性越来越差,复杂度越来越高。
但解决这个问题的几种方案都并不复杂。这些示例之所以简单,本质上是因为高级编程语言强大的表达能力已经能够不依赖于各种模式的模板代码,为需求提供直接的语义支持,而无需套用各种设计模式的八股文。
当然,你可以用模式来概括一些降低业务逻辑复杂度的技巧,但如果生搬硬套地记忆并使用模式,同样可能会走进过度设计的歧途。在实现常见业务功能时,掌握好编程语言,梳理好需求,用最简单的代码将其实现,就已经是最优解了。

