
React 中同构(SSR)原理脉络梳理
前言
一个段子:上午写React,下午写Vue,晚上再补一个小程序、快应用。今日早读文章由阿里@ES2049 Studio分享。
正文从这开始~~

随着越来越多新型前端框架的推出,SSR 这个概念在前端开发领域的流行度越来越高,也有越来越多的项目采用这种技术方案进行了实现。SSR 产生的背景是什么?适用的场景是什么?实现的原理又是什么?希望大家在这篇文章中能够找到你想要的答案。
说到 SSR,很多人的第一反应是“服务器端渲染”,但我更倾向于称之为“同构”,所以首先我们来对“客户端渲染”,“服务器端渲染”,“同构”这三个概念简单的做一个分析:
客户端渲染:客户端渲染,页面初始加载的 HTML 页面中无网页展示内容,需要加载执行JavaScript 文件中的 React 代码,通过 JavaScript 渲染生成页面,同时,JavaScript 代码会完成页面交互事件的绑定,详细流程可参考下图(图片取材自 fullstackacademy.com):
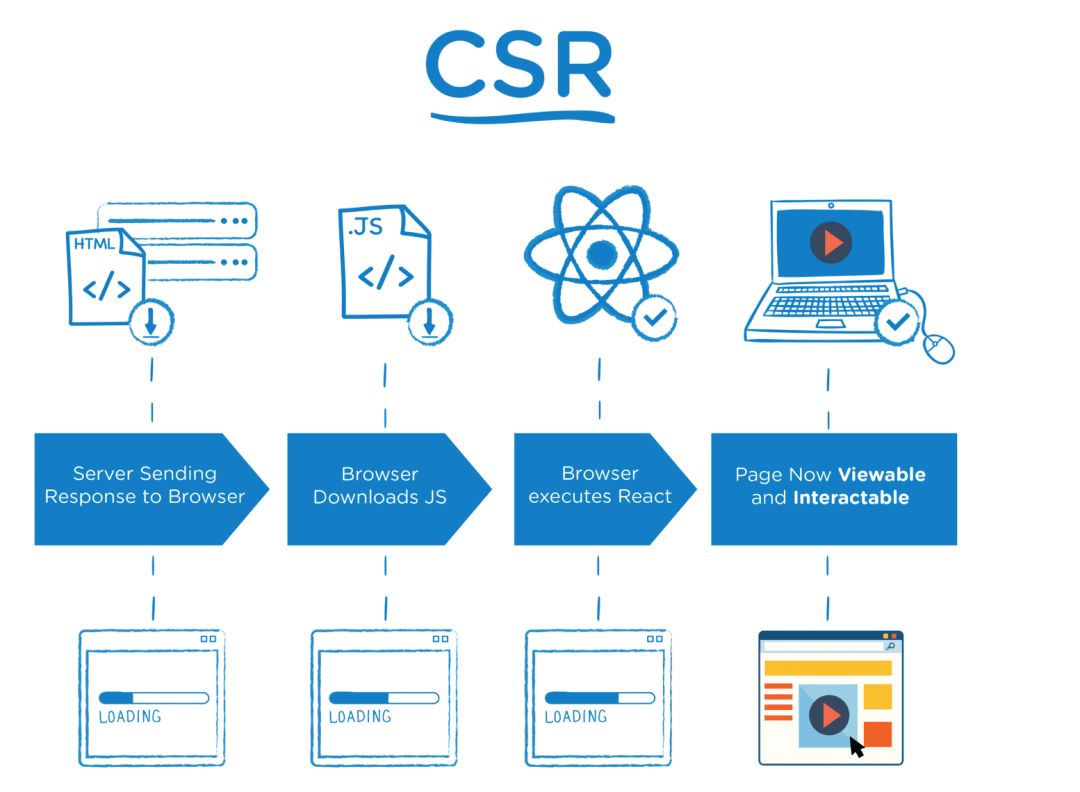
服务器端渲染:用户请求服务器,服务器上直接生成 HTML 内容并返回给浏览器。服务器端渲染来,页面的内容是由 Server 端生成的。一般来说,服务器端渲染的页面交互能力有限,如果要实现复杂交互,还是要通过引入 JavaScript 文件来辅助实现。服务器端渲染这个概念,适用于任何后端语言。
同构:同构这个概念存在于 Vue,React 这些新型的前端框架中,同构实际上是客户端渲染和服务器端渲染的一个整合。我们把页面的展示内容和交互写在一起,让代码执行两次。在服务器端执行一次,用于实现服务器端渲染,在客户端再执行一次,用于接管页面交互,详细流程可参考下图(图片取材自 fullstackacademy.com):
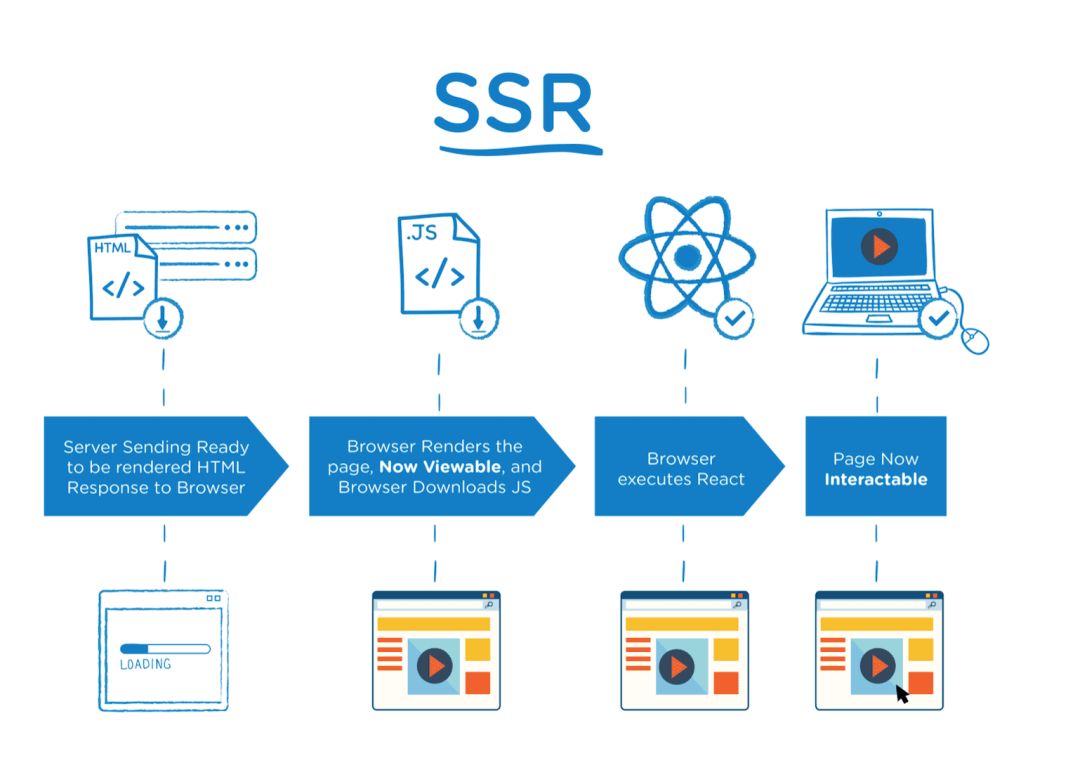
一般情况下,当我们使用 React 编写代码时,页面都是由客户端执行 JavaScript 逻辑动态挂 DOM 生成的,也就是说这种普通的单页面应用实际上采用的是客户端渲染模式。在大多数情况下,客户端渲染完全能够满足我们的业务需求,那为什么我们还需要 SSR 这种同构技术呢?
使用 SSR 技术的主要因素:
CSR 项目的 TTFP(Time To First Page)时间比较长,参考之前的图例,在 CSR 的页面渲染流程中,首先要加载 HTML 文件,之后要下载页面所需的 JavaScript 文件,然后 JavaScript 文件渲染生成页面。在这个渲染过程中至少涉及到两个 HTTP 请求周期,所以会有一定的耗时,这也是为什么大家在低网速下访问普通的 React 或者 Vue 应用时,初始页面会有出现白屏的原因。
CSR 项目的 SEO 能力极弱,在搜索引擎中基本上不可能有好的排名。因为目前大多数搜索引擎主要识别的内容还是 HTML,对 JavaScript 文件内容的识别都还比较弱。如果一个项目的流量入口来自于搜索引擎,这个时候你使用 CSR 进行开发,就非常不合适了。
SSR 的产生,主要就是为了解决上面所说的两个问题。在 React 中使用 SSR 技术,我们让 React 代码在服务器端先执行一次,使得用户下载的 HTML 已经包含了所有的页面展示内容,这样,页面展示的过程只需要经历一个 HTTP 请求周期,TTFP 时间得到一倍以上的缩减。
同时,由于 HTML 中已经包含了网页的所有内容,所以网页的 SEO 效果也会变的非常好。之后,我们让 React 代码在客户端再次执行,为 HTML 网页中的内容添加数据及事件的绑定,页面就具备了 React 的各种交互能力。
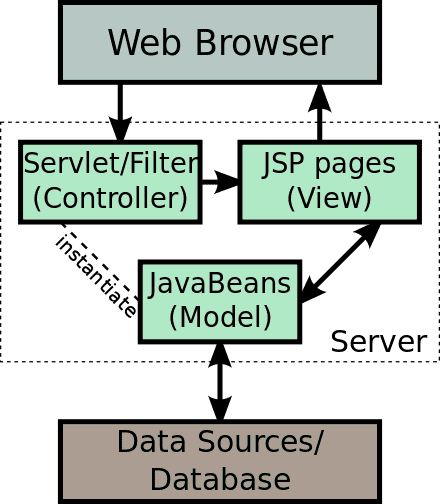
但是,SSR 这种理念的实现,并非易事。我们来看一下在 React 中实现 SSR 技术的架构图:
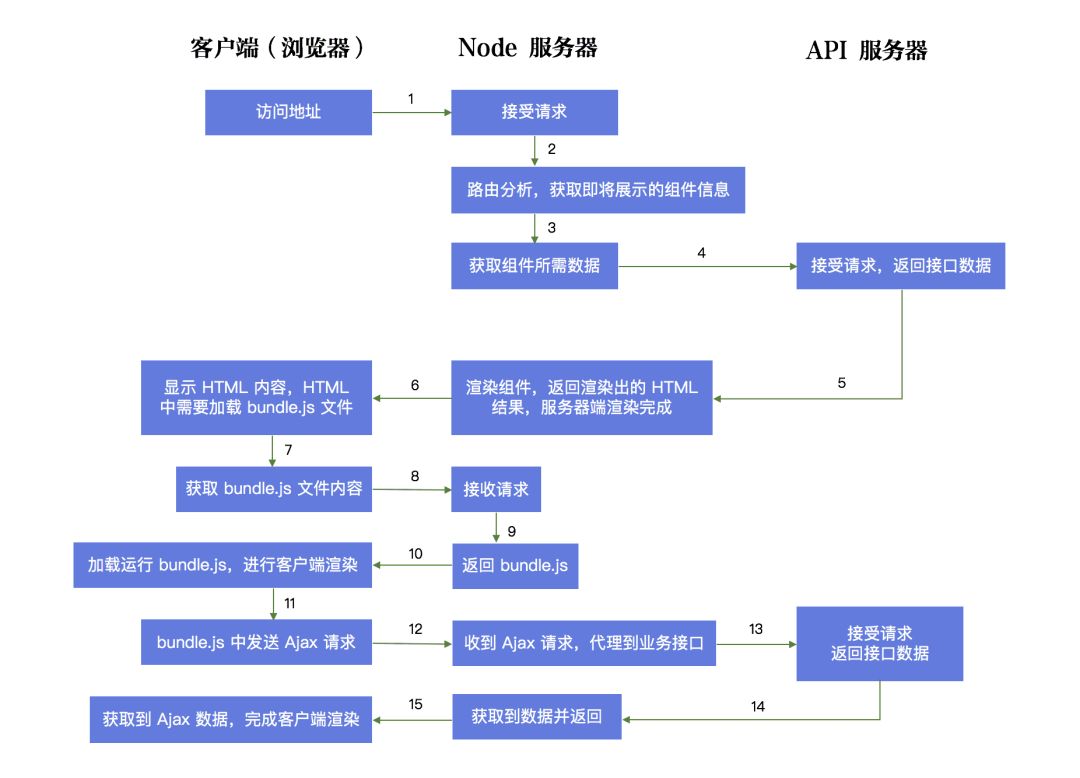
使用 SSR 这种技术,将使原本简单的 React 项目变得非常复杂,项目的可维护性会降低,代码问题的追溯也会变得困难。
所以,使用 SSR 在解决问题的同时,也会带来非常多的副作用,有的时候,这些副作用的伤害比起 SSR 技术带来的优势要大的多。从个人经验上来说,我一般建议大家,除非你的项目特别依赖搜索引擎流量,或者对首屏时间有特殊的要求,否则不建议使用 SSR。
好,如果你确实遇到了 React 项目中要使用 SSR 的场景并决定使用 SSR,那么接下来我们就结合上面这张 SSR 架构图,开启 SSR 技术点的难点剖析。
在开始之前,我们先来分析下虚拟 DOM 和 SSR 的关系。
SSR 之所以能够实现,本质上是因为虚拟 DOM 的存在
上面我们说过,SSR 的工程中,React 代码会在客户端和服务器端各执行一次。你可能会想,这没什么问题,都是 JavaScript 代码,既可以在浏览器上运行,又可以在 Node 环境下运行。但事实并非如此,如果你的 React 代码里,存在直接操作 DOM 的代码,那么就无法实现 SSR 这种技术了,因为在 Node 环境下,是没有 DOM 这个概念存在的,所以这些代码在 Node 环境下是会报错的。
好在 React 框架中引入了一个概念叫做虚拟 DOM,虚拟 DOM 是真实 DOM 的一个 JavaScript 对象映射,React 在做页面操作时,实际上不是直接操作 DOM,而是操作虚拟 DOM,也就是操作普通的 JavaScript 对象,这就使得 SSR 成为了可能。在服务器,我可以操作 JavaScript 对象,判断环境是服务器环境,我们把虚拟 DOM 映射成字符串输出;在客户端,我也可以操作 JavaScript 对象,判断环境是客户端环境,我就直接将虚拟 DOM 映射成真实 DOM,完成页面挂载。
其他的一些框架,比如 Vue,它能够实现 SSR 也是因为引入了和 React 中一样的虚拟 DOM 技术。
好,接下来我们回过头看流程图,前两步不说了,服务器端渲染肯定要先向 Node 服务器发送请求。重点是第 3 步,大家可以看到,服务器端要根据请求的地址,判断要展示什么样的页面了,这一步叫做服务器端路由。
我们再看第 10 步,当客户端接收到 JavaScript 文件后,要根据当前的路径,在浏览器上再判断当前要展示的组件,重新进行一次客户端渲染,这个时候,还要经历一次客户端路由(前端路由)。
那么,我们下面要说的就是服务器端路由和客户端路由的区别。
SSR 中客户端渲染与服务器端渲染路由代码的差异
实现 React 的 SSR 架构,我们需要让相同的 React 代码在客户端和服务器端各执行一次。大家注意,这里说的相同的 React 代码,指的是我们写的各种组件代码,所以在同构中,只有组件的代码是可以公用的,而路由这样的代码是没有办法公用的,大家思考下这是为什么呢?其实原因很简单,在服务器端需要通过请求路径,找到路由组件,而在客户端需通过浏览器中的网址,找到路由组件,是完全不同的两套机制,所以这部分代码是肯定无法公用。我们来看看在 SSR 中,前后端路由的实现代码:
客户端路由:
const App = () => {
return (
<Provider store={store}>
<BrowserRouter>
<div>
<Route path='/' component={Home}>
</div>
</BrowserRouter>
</Provider>
)
}
ReactDom.render(<App/>, document.querySelector('#root'))客户端路由代码非常简单,大家一定很熟悉,BrowserRouter 会自动从浏览器地址中,匹配对应的路由组件显示出来。
服务器端路由代码:
const App = () => {
return
<Provider store={store}>
<StaticRouter location={req.path} context={context}>
<div>
<Route path='/' component={Home}>
</div>
</StaticRouter>
</Provider>
}
Return ReactDom.renderToString(<App/>)服务器端路由代码相对要复杂一点,需要你把 location(当前请求路径)传递给 StaticRouter 组件,这样 StaticRouter 才能根据路径分析出当前所需要的组件是谁。(PS:StaticRouter 是 React-Router 针对服务器端渲染专门提供的一个路由组件。)
通过 BrowserRouter 我们能够匹配到浏览器即将显示的路由组件,对浏览器来说,我们需要把组件转化成 DOM,所以需要我们使用 ReactDom.render 方法来进行 DOM 的挂载。而 StaticRouter 能够在服务器端匹配到将要显示的组件,对服务器端来说,我们要把组件转化成字符串,这时我们只需要调用 ReactDom 提供的 renderToString 方法,就可以得到 App 组件对应的 HTML 字符串。
对于一个 React 应用来说,路由一般是整个程序的执行入口。在 SSR 中,服务器端的路由和客户端的路由不一样,也就意味着服务器端的入口代码和客户端的入口代码是不同的。
我们知道, React 代码是要通过 Webpack 打包之后才能运行的,也就是第 3 步和第10 步运行的代码,实际上是源代码打包过后生成的代码。上面也说到,服务器端和客户端渲染中的代码,只有一部分一致,其余是有区别的。所以,针对代码运行环境的不同,要进行有区别的 Webpack 打包。
服务器端代码和客户端代码的打包差异
简单写两个 Webpack 配置文件作为 DEMO:
客户端 Webpack 配置:
{
entry: './src/client/index.js',
output: {
filename: 'index.js',
path: path.resolve(__dirname, 'public')
},
module: {
rules: [{
test: /.js?$/,
loader: 'babel-loader'
},{
test: /.css?$/,
use: ['style-loader', {
loader: 'css-loader',
options: {modules: true}
}]
},{
test: /.(png|jpeg|jpg|gif|svg)?$/,
loader: 'url-loader',
options: {
limit: 8000,
publicPath: '/'
}
}]
}
}服务器端 Webpack 配置:
{
target: 'node',
entry: './src/server/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'build')
},
externals: [nodeExternals()],
module: {
rules: [{
test: /.js?$/,
loader: 'babel-loader'
},{
test: /.css?$/,
use: ['isomorphic-style-loader', {
loader: 'css-loader',
options: {modules: true}
}]
},{
test: /.(png|jpeg|jpg|gif|svg)?$/,
loader: 'url-loader',
options: {
limit: 8000,
outputPath: '../public/',
publicPath: '/'
}
}]
}
};上面我们说了,在 SSR 中,服务器端渲染的代码和客户端的代码的入口路由代码是有差异的,所以在 Webpack 中,Entry 的配置首先肯定是不同的。
在服务器端运行的代码,有时我们需要引入 Node 中的一些核心模块,我们需要 Webpack 做打包的时候能够识别出类似的核心模块,一旦发现是核心模块,不必把模块的代码合并到最终生成的代码中,解决这个问题的方法非常简单,在服务器端的 Webpack配置中,你只要加入 target: node 这个配置即可。
服务器端渲染的代码,如果加载第三方模块,这些第三方模块也是不需要被打包到最终的源码中的,因为 Node 环境下通过 NPM 已经安装了这些包,直接引用就可以,不需要额外再打包到代码里。为了解决这个问题,我们可以使用 webpack-node-externals 这个插件,代码中的 nodeExternals 指的就是这个插件,通过这个插件,我们就能解决这个问题。关于 Node 这里的打包问题,可能看起来有些抽象,不是很明白的同学可以仔细读一下 webpack-node-externals 相关的文章或文档,你就能很好的明白这里存在的问题了。
接下来我们继续分析,当我们的 React 代码中引入了一些 CSS 样式代码时,服务器端打包的过程会处理一遍 CSS,而客户端又会处理一遍。查看配置,我们可以看到,服务器端打包时我们用了 isomorphic-style-loader,它处理 CSS 的时候,只在对应的 DOM 元素上生成 class 类名,然后返回生成的 CSS 样式代码。
而在客户端代码打包配置中,我们使用了 css-loader 和 style-loader,css-loader 不但会在 DOM 上生成 class 类名,解析好的 CSS 代码,还会通过 style-loader 把代码挂载到页面上。不过这么做,由于页面上的样式实际上最终是由客户端渲染时添加上的,所以页面可能会存在一开始没有样式的情况,为了解决这个问题, 我们可以在服务器端渲染时,拿到 isomorphic-style-loader 返回的样式代码,然后以字符串的形式添加到服务器端渲染的 HTML 之中。
而对于图片等类型的文件引入,url-loader 也会在服务器端代码和客户端代码打包的过程中分别进行打包,这里,我偷了一个懒,无论服务器端打包还是客户端打包,我都让打包生成的文件存储在 public 目录下,这样,虽然文件会打包出来两遍,但是后打包出来的文件会覆盖之前的文件,所以看起来还是只有一份文件。
当然,这样做的性能和优雅性并不高,只是给大家提供一个小的思路,如果想进行优化,你可以让图片的打包只进行一次,借助一些 Webpack 的插件,实现这个也并非难事,你甚至可以自己也写一个 loader,来解决这样的问题。
如果你的 React 应用中没有异步数据的获取,单纯的做一些静态内容展示,经过上面的配置,你会发现一个简单的 SSR 应用很快的就可以被实现出来了。但是,真正的一个 React 项目中,我们肯定要有异步数据的获取,绝大多数情况下,我们还要使用 Redux 管理数据。而如果想在 SSR 应用中实现,就不是这么简单了。
SSR 中异步数据的获取 + Redux 的使用
客户端渲染中,异步数据结合 Redux 的使用方式遵循下面的流程(对应图中第 12 步):
创建 Store
根据路由显示组件
派发 Action 获取数据
更新 Store 中的数据
组件 Rerender
而在服务器端,页面一旦确定内容,就没有办法 Rerender 了,这就要求组件显示的时候,就要把 Store 的数据都准备好,所以服务器端异步数据结合 Redux 的使用方式,流程是下面的样子(对应图中第 4 步):
创建 Store
根据路由分析 Store 中需要的数据
派发 Action 获取数据
更新Store 中的数据
结合数据和组件生成 HTML,一次性返回
下面,我们分析下服务器端渲染这部分的流程:
创建 Store:这一部分有坑,要注意避免,大家知道,客户端渲染中,用户的浏览器中永远只存在一个 Store,所以代码上你可以这么写:
const store = createStore(reducer, defaultState)
export default store;然而在服务器端,这么写就有问题了,因为服务器端的 Store 是所有用户都要用的,如果像上面这样构建 Store,Store 变成了一个单例,所有用户共享 Store,显然就有问题了。所以在服务器端渲染中,Store 的创建应该像下面这样,返回一个函数,每个用户访问的时候,这个函数重新执行,为每个用户提供一个独立的 Store:
const getStore = (req) => {
return createStore(reducer, defaultState);
}
export default getStore;根据路由分析 Store 中需要的数据: 要想实现这个步骤,在服务器端,首先我们要分析当前出路由要加载的所有组件,这个时候我们可以借助一些第三方的包,比如说 react-router-config, 具体这个包怎么使用,不做过多说明,大家可以查看文档,使用这个包,传入服务器请求路径,它就会帮助你分析出这个路径下要展示的所有组件。
派发 Action 获取数据: 接下来,我们在每个组件上增加一个获取数据的方法:
```
Home.loadData = (store) => {
return store.dispatch(getHomeList())
}“`
这个方法需要你把服务器端渲染的 Store 传递进来,它的作用就是帮助服务器端的 Store 获取到这个组件所需的数据。 所以,组件上有了这样的方法,同时我们也有当前路由所需要的所有组件,依次调用各个组件上的 loadData 方法,就能够获取到路由所需的所有数据内容了。
更新 Store 中的数据: 其实,当我们执行第三步的时候,已经在更新 Store 中的数据了,但是,我们要在生成 HTML 之前,保证所有的数据都获取完毕,这怎么处理呢?
// matchedRoutes 是当前路由对应的所有需要显示的组件集合
matchedRoutes.forEach(item => {
if (item.route.loadData) {
const promise = new Promise((resolve, reject) => {
item.route.loadData(store).then(resolve).catch(resolve);
})
promises.push(promise);
}
})
Promise.all(promises).then(() => {
// 生成 HTML 逻辑
})这里,我们使用 Promise 来解决这个问题,我们构建一个 Promise 队列,等待所有的 Promise 都执行结束后,也就是所有 store.dispatch 都执行完毕后,再去生成 HTML。这样的话,我们就实现了结合 Redux 的 SSR 流程。
在上面,我们说到,服务器端渲染时,页面的数据是通过 loadData 函数来获取的。而在客户端,数据获取依然要做,因为如果这个页面是你访问的第一个页面,那么你看到的内容是服务器端渲染出来的,但是如果经过 react-router 路由跳转道第二个页面,那么这个页面就完全是客户端渲染出来的了,所以客户端也要去拿数据。
在客户端获取数据,使用的是我们最习惯的方式,通过 componentDidMount 进行数据的获取。这里要注意的是,componentDidMount 只在客户端才会执行,在服务器端这个生命周期函数是不会执行的。所以我们不必担心 componentDidMount 和 loadData 会有冲突,放心使用即可。这也是为什么数据的获取应该放到 componentDidMount 这个生命周期函数中而不是 componentWillMount 中的原因,可以避免服务器端获取数据和客户端获取数据的冲突。
Node 只是一个中间层
上一部分我们说到了获取数据的问题,在 SSR 架构中,一般 Node 只是一个中间层,用来做 React 代码的服务器端渲染,而 Node 需要的数据通常由 API 服务器单独提供。
这样做一是为了工程解耦,二也是为了规避 Node 服务器的一些计算性能问题。
请大家关注图中的第 4 步和第 12,13 步,我们接下来分析这几个步骤。
服务器端渲染时,直接请求 API 服务器的接口获取数据没有任何问题。但是在客户端,就有可能存在跨域的问题了,所以,这个时候,我们需要在服务器端搭建 Proxy 代理功能,客户端不直接请求 API 服务器,而是请求 Node 服务器,经过代理转发,拿到 API 服务器的数据。
这里你可以通过 express-http-proxy 这样的工具帮助你快速搭建 Proxy 代理功能,但是记得配置的时候,要让代理服务器不仅仅帮你转发请求,还要把 cookie 携带上,这样才不会有权限校验上的一些问题。
// Node 代理功能实现代码
app.use('/api', proxy('http://apiServer.com', {
proxyReqPathResolver: function (req) {
return '/ssr' + req.url;
}
}));总结:
到这里,整个 SSR 的流程体系中关键知识点的原理就串联起来了,如果你之前适用过 SSR 框架,那么这些知识点的整理我相信可以从原理层面很好的帮助到你。
当然,我也考虑到阅读本篇文章的同学可能有很大一部分对 SSR 的基础知识非常有限,看了文章可能会云里雾里,这里为了帮助这些同学,我编写了一个非常简单的 SSR 框架,代码放在这里:
https://files.alicdn.com/tpsservice/bf46acacaab649752e9c9121bdfb7f70.zip
初学者结合上面的流程图,一步步梳理流程图中的逻辑,梳理结束后,回来再看一遍这篇文章,相信大家就豁然开朗了。
当然在真正实现 SSR 架构的过程中,难点有时不是实现的思路,而是细节的处理。比如说如何针对不同页面设置不同的 title 和 description 来提升 SEO 效果,这时候,我们其实可以用 react-helmet 这样的工具帮我们达成目标,这个工具对客户端和服务器端渲染的效果都很棒,值得推荐。还有一些诸如工程目录的设计,404,301 重定向情况的处理等等,不过这些问题,我们只需要在实践中遇到的时候逐个攻破就可以了。
好了,关于 SSR 的全部分享就到这里,希望这篇文章能够或多或少帮助到你。
参考文档
Webpack 官方网站
What is React Server Side Rendering and should I use it?
StaticRouter
The Pain and the Joy of creating isomorphic apps in ReactJS
关于本文
作者:@ES2049 Studio
原文:https://www.yuque.com/es2049/blog/zy0eq0

